差错控制编码¶
约 4175 个字 预计阅读时间 23 分钟
- 包含于【信道编码】,增加冗余以纠正检查传输差错,降低 \(P_{e}\)
- 降低有效性为代价换取有效性 最经典莫过于【奇偶校验】
- 不同的编码方法,需要分析其【纠错能力】
收发框图
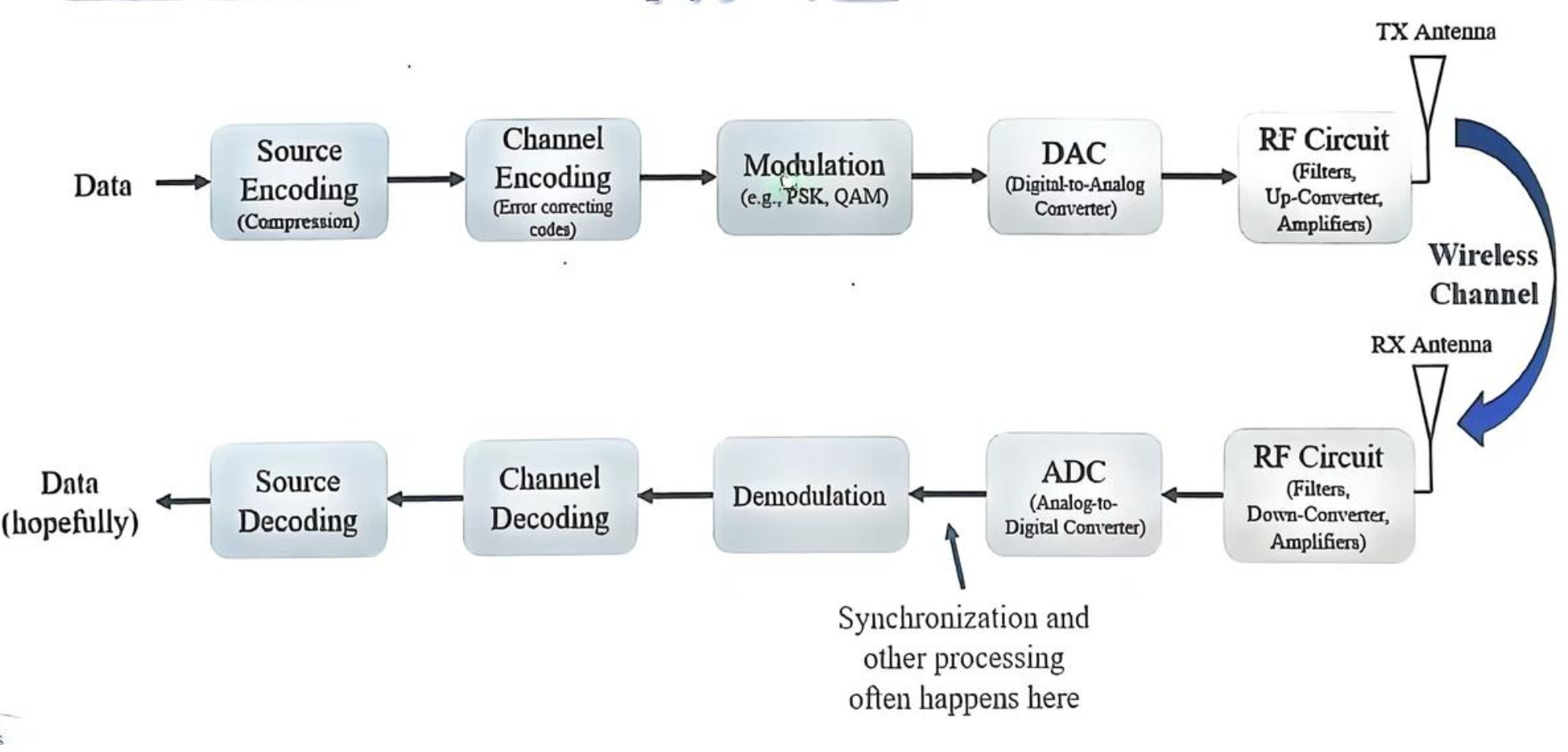
差错控制引入¶
存在乘性干扰(信道引入)与加性噪声

针对不同的信道因地制宜使用差错控制方式
信道类型¶
- 随机信道:错码独立出现
- 突发信道:脉冲信号引发的集中错码
- 混合信道:混合随机与突发信道
差错控制方式¶
- 检错重发【自动重传请求(Automatic Repeat-reQuest,ARQ)】
- 前向纠错(Forward Error Correction,FEC)
- 混合自动重传(HARQ)【结合 ARQ 与 FEC】
- 反馈校验
- 检错删除(常用于语音传输)
三种 ARQ 系统¶
回忆 GBN 与 SR
即等待重传
一一在发送下一个码组之前,要等待来自接收机的 ACK。
发送码组
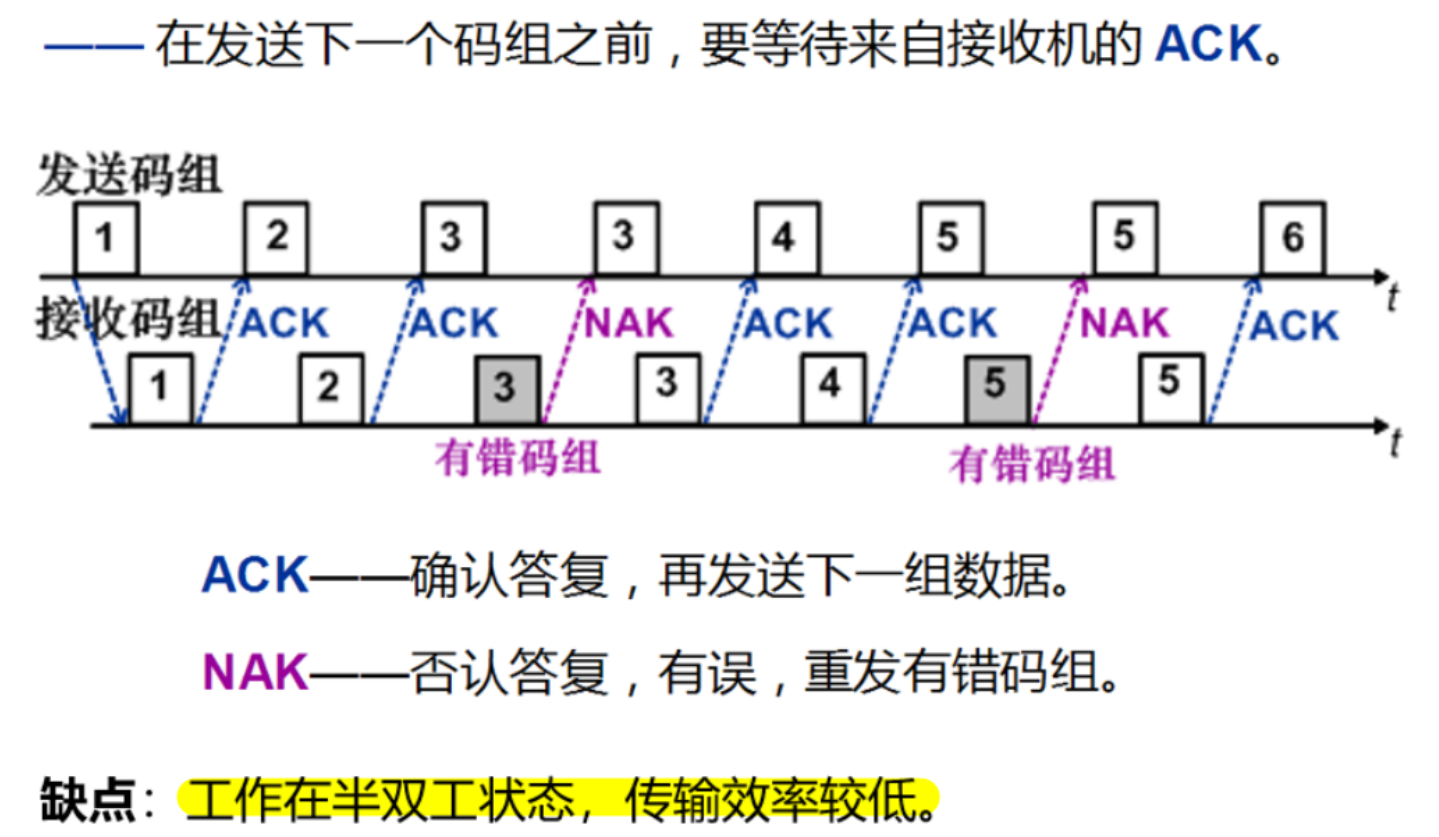
即 GBN
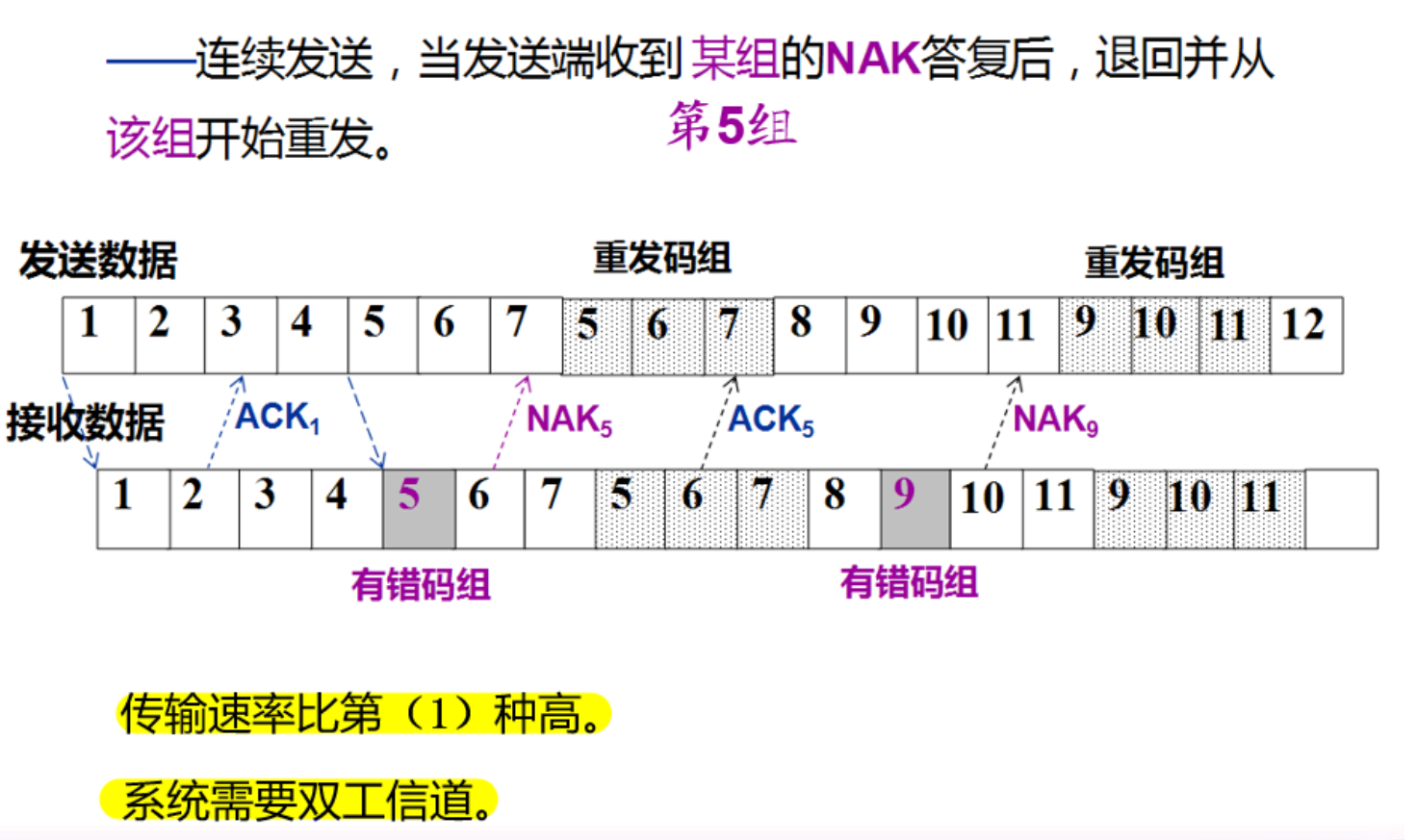
即 SR
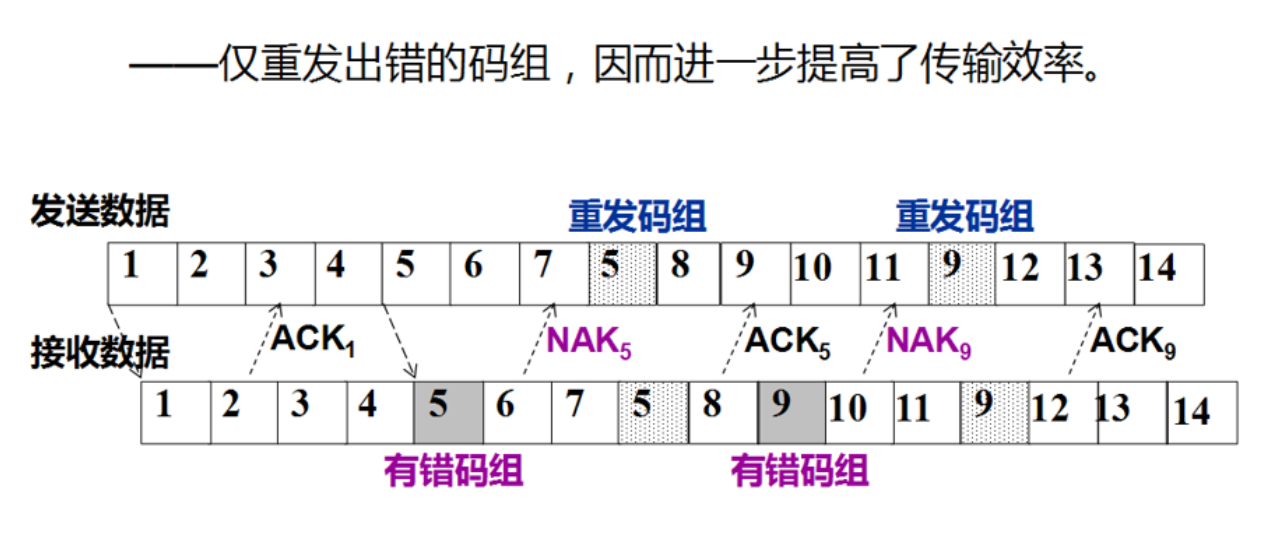
ARQ 的优缺点¶
理解为主
- 【码率】 (不是码元速率)较高
- 检错复杂度低
- 编码方法与加性干扰统计特征基本无关,信道泛用性好
- 需要双工通信
- 重发占缓存,且延迟较大,不适用于实时(联想 TCP 与 UDP)
ARQ 系统原理框图
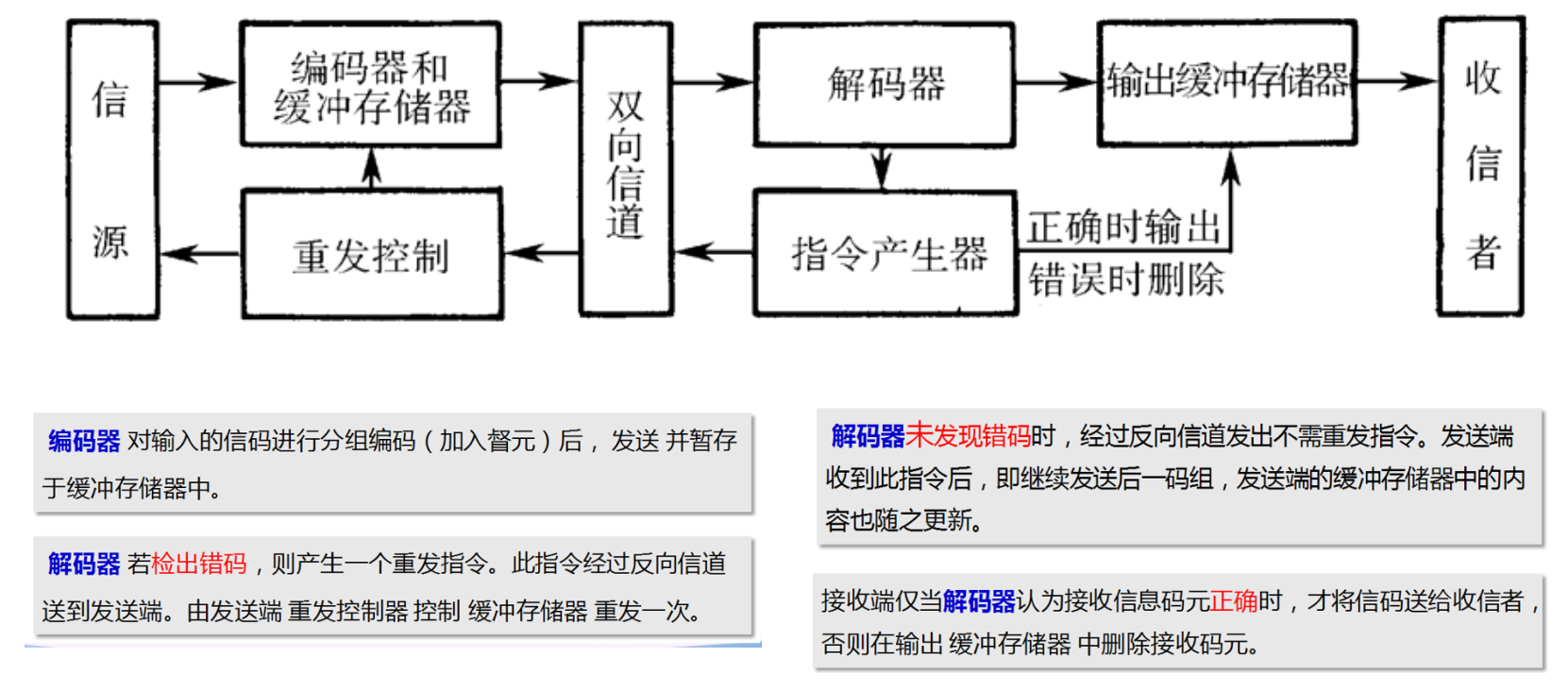
纠错编码¶
回忆:禁用/许用码组
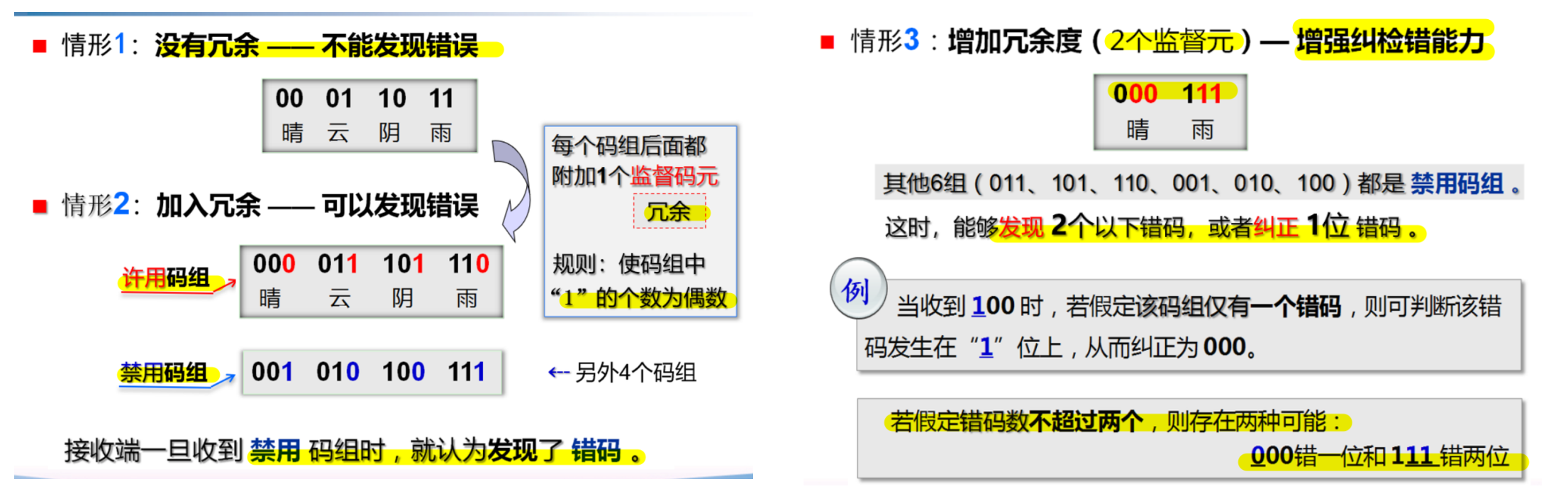
概念引入¶
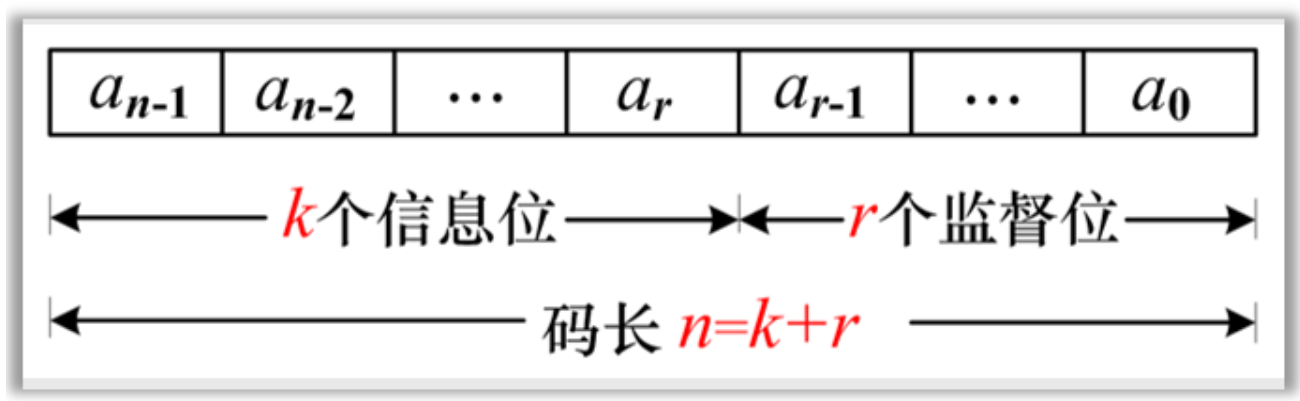
- 监督码元:冗余码元,又称为督元,用
r表示 - 信息码元:又称为信元,用
k表示 - 码长:码元个数,用
n表示 - 多余度: \(\frac{r}{n}\)
- 码率(编码效率): \(R_{c}={\frac{k}{n}}\)
这里与【码元速率】区别码重:码组中的1个数,用w表示 - 码距:两 许用码组 对应位不同的个数(异或求和),称为【汉明距离】,用
d表示 - 最小码距\(d_{0}\):所有 许用码组 之间码距的最小值
对于线性码,最小码距等于非全零码的最小重量,即 \(d_{0}=w_{0}\)
分组码¶
包含信息码元(信元 k)与监督码元(督元,r)的编码,用 (n,k) 表示
注意
在分组码中,督元仅与本组信元相关(仅仅监督本组,而与其他组无关)
这一点区别于卷积码
系统码
码组按照 {k,r} 方式排列结构的分组码称为【系统码】
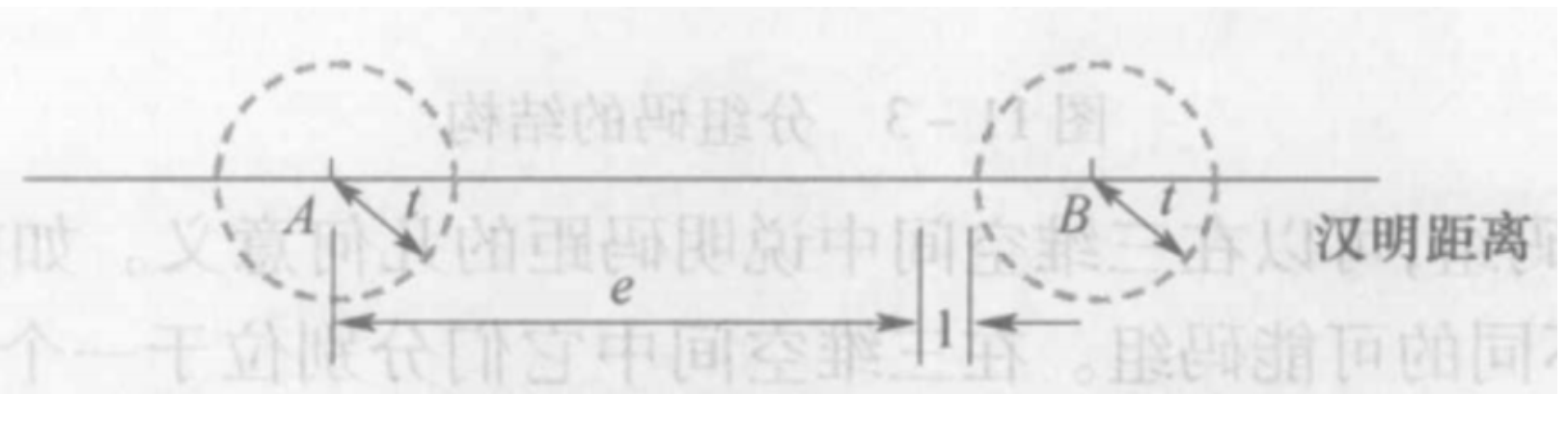
最小码距与检纠能力的关系¶
- 能检查出
e个错码,需要 \(d_{0}\geq e+1\)
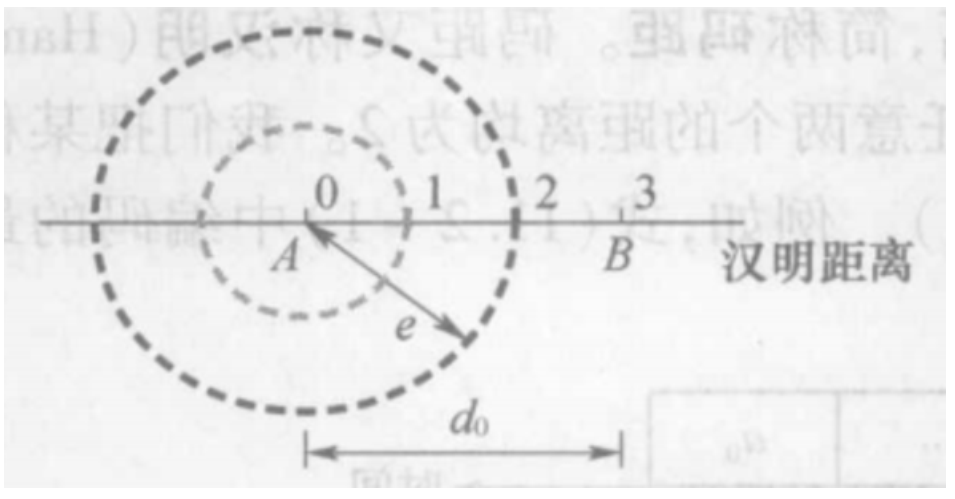
上图可以检查出的错码为{0,1,2}
- 能纠正
t个错码,需要 \(d_{0}\geq2t+1\) ,即圆不重合
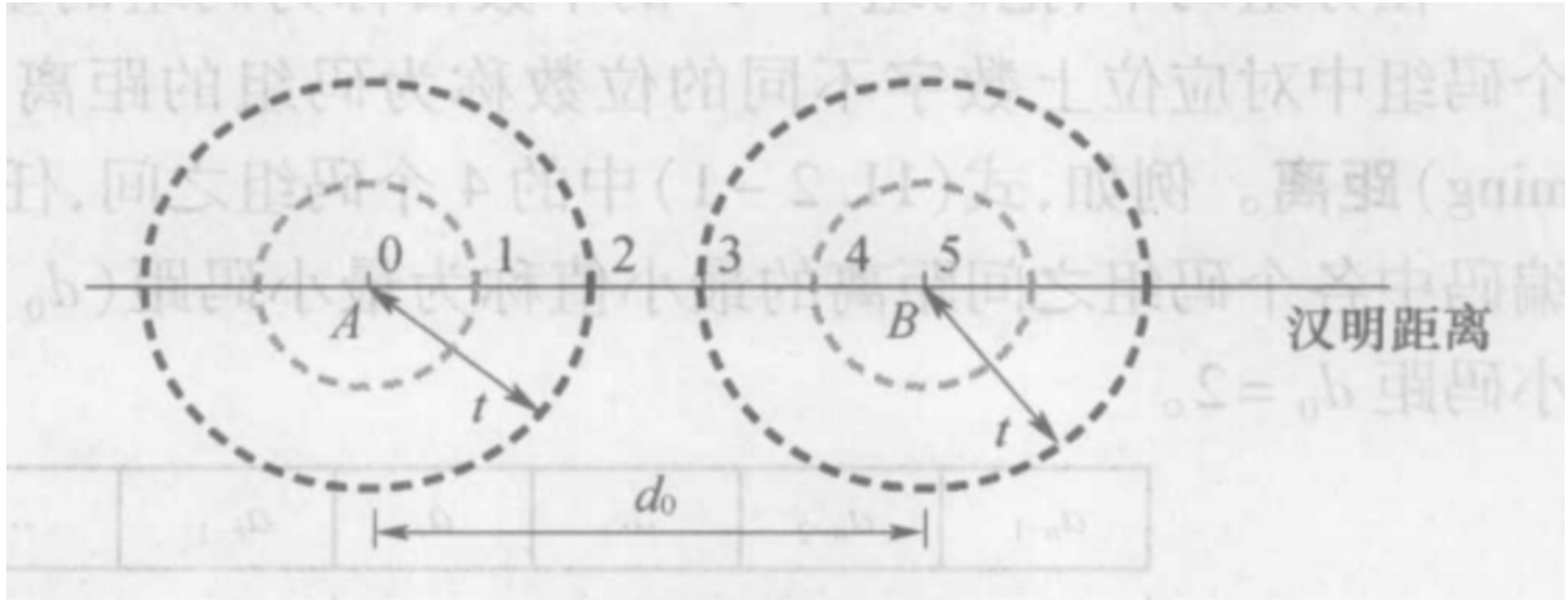
- 同时纠正
t个错码与检查e个错码。需要 \(d_{0}\geq e+t+1\) \((e>t)\)
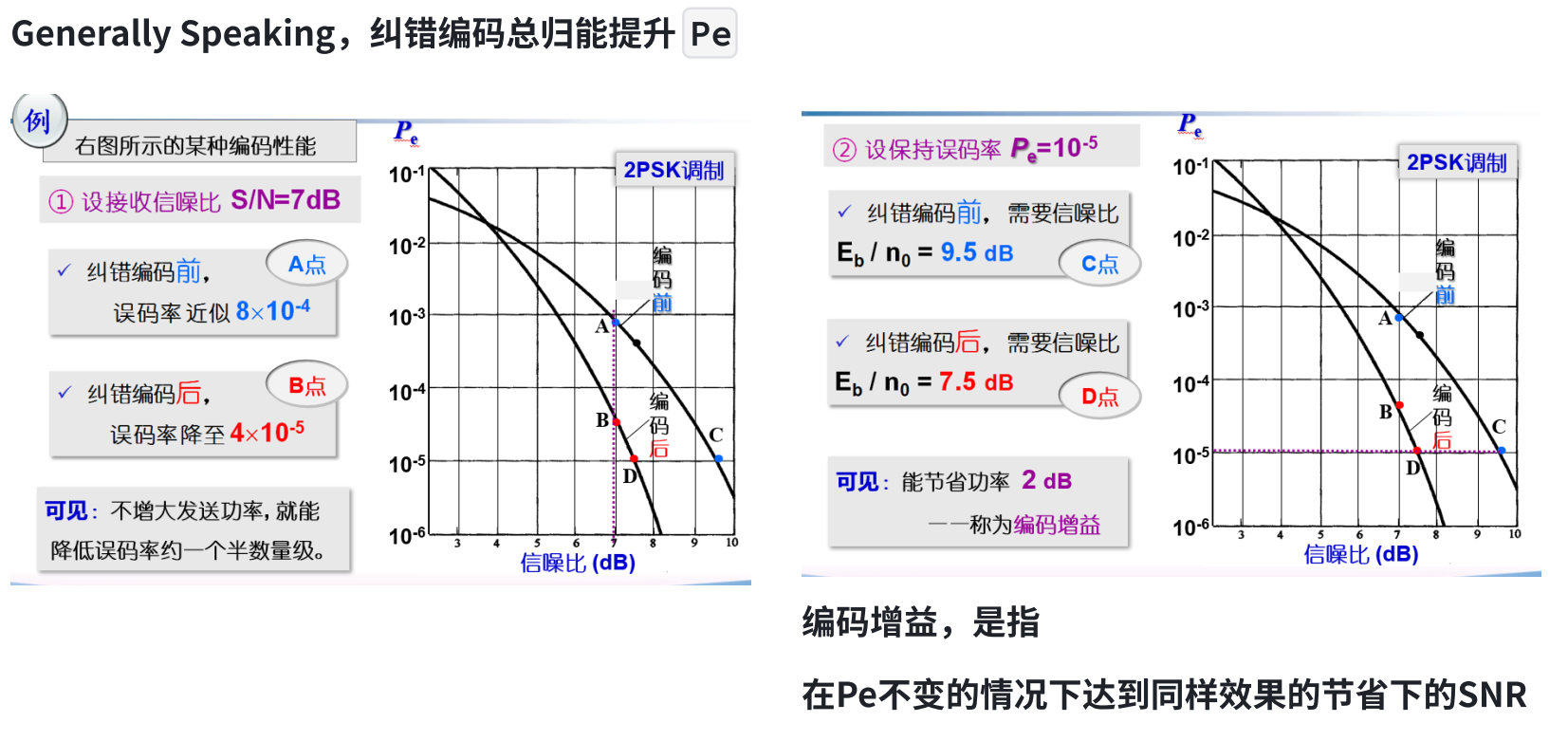
纠错编码,有用吗?
引入督元,则序列变长;信息码元速率不变,则传输速率需要增大
信号序列周期变短,频域上带宽展宽
对于白噪声,噪声功率增大,SNR 下降,使得接收错码增多 😭
题外话—比特信噪比 Eb/N0
- SNR(Signal-Noise Ratio)即信噪比,在模拟通信系统中,是接收端模拟信号的重要测量指标,可以通过频谱仪等仪器直接实际测量接收端的模拟信号得到
- Eb/N0 则是指通信系统中传输一比特信息所需要的能量和噪声功率谱密度的比值,是衡量整个通信系统性能归一化的一个性能指标
在数字通信工程中,SNR 无法体现频谱效率的作用 因此如果想要将系统效率的作用排除在外,就必须从单个比特着手去比较,故而采用 Eb/N0
- 两者之间的转换关系
Rc:通信系统的信道编码速率;
Rm:通信系统的调制率, \(\scriptstyle\mathrm{Rm=log2(M),M}\) 是调制星座点个数;
d: 扩频倍数;
insValue : 平方根升余弦滚降成型滤波器的插值倍数;
对于 FDMA 和 TDMA 体制通信系统, 令 \(U=1\) 即可
简单的实用编码¶
了解一下概念就行 | 知道 模 2 加
即奇偶校验,添加督元使得码组 1 为奇数/偶数
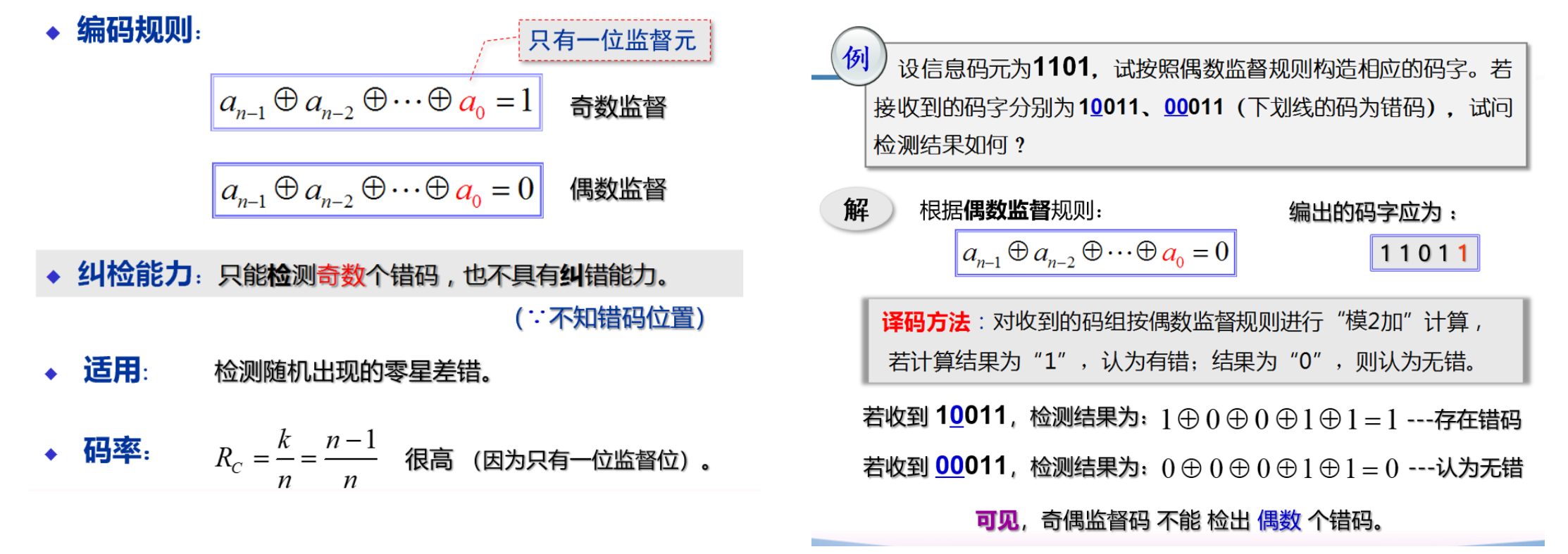
采用【模 2 加】译码,即 逐位异或 或 二进制加法
不能检出偶数个错误

类似单片机中的 Key 检测

此码可纠错

(n,k)线性分组码¶
按照一组线性方程构成的分组码
线性码:督元是信元的线性组合
校正子 \(S=a_{n-1}\oplus a_{n-2}\oplus\cdots\oplus a_{0}\)
偶监督下\({}=0\) 则无错,否则认为有错
若希望用 r 个督元纠错一位错码 ,则 r 至少满足
\(2^{r}-1\geq n\) 或 \(2^{r}\geq k+r+1\)
取等号即为汉明码,即 \(\boxed{(n,k)=(2^{r}-1,2^{r}-1-r)}\)
如何理解 \(2^{r}-1\geq n\)?
欲满足纠正一位错码,需要使得 r 位错码能通过排列组合一一映射
对于 n 位长度的码组,共有 n+1 种可能,包含第 n 位错码 + 没有错误
而 r 位督元可以表示 \(2^{r}\) 种可能,故得到结果
进一步的,若欲满足至少纠正 2 位错码,得 \(2^{r}-1\geq n+C_{n}^{2}=n+\frac{n(n-1)}{2}\)
以(7,4)汉明码为例¶
仍在偶监督下
- 接收端
先【规定】校正子矩阵结果与错码位置的对应关系【监督关系式】
自定义,没有绝对,一一对应即可 | 监督位出现在只出现 单1 的位置
根据 1 的位置写出【监督关系式】
- 发射端
根据监督关系式产生督元
最后可通过排列得 16 个许用码组
最小码距 \(d_{0}\) 为
3,最多能纠错1个错码

线性分组码的一般化表达¶
将监督关系式改为监督方程
改写成监督矩阵的形式
即
为
(r·n)的矩阵,每一列为错码位置对应的监督表达式
无错码情况下
码组为 A。故可简记为
对于典型监督矩阵 H,可写作
将信元矩阵称为 P阵(r·k)

同样可由
归纳出矩阵表达式
现希望有【生成矩阵】,要求
观察得,将 P 转置后(Q 阵 ) 左侧添加 (k·k) 的单位阵
此即为典型生成矩阵(左边为单位阵 I)

你不得不知道的
让我们充分理解这一句话
G 的各行本身就是一个码组
∴ 若有\(k\)个线性无关的码组,则可用其作为生成矩阵 \(G\) ,并由它生成其余码组
这句话中 imply 两条信息:
- 生成矩阵的【每一行】都是一个【许用码组】
我们知道其是由 单位阵(用于表示信息阵码组)与对应的监督关系式 组成的
∴ 每一行当然就是一个许用码组,这就是生成矩阵的意义 | 不信你对照着瞄一眼
而把思维逆转过来,这是不是表明,当已知上面的许用码组时,能直接反向解析出生成矩阵呢?
那么监督矩阵也就信手拈来了
- 非典型矩阵可通过行列变换变成典型矩阵
结合第一点,我们能得出推断:若所给许用码组构成的生成矩阵并不典型,则可以通过行变换转换为典型
监督矩阵与生成矩阵的关系总结

校正子与错误图样¶
- 错误图样(错码矩阵)
显示哪里错了
- 校正子
就是前面的
S,指出哪个错了
若接收码组为 B,则此码组的校正子为
所以
故得到译码完整步骤:计算 S,找出错误码位置,纠正
由接收到的码组 \(B\) 计算 : \(S=B\cdot H^{\intercal}\) ;
由 \(S\) 找到错误图样 \(E\) ;
由公式 \(A=B+E\) 得到译码器译出的码组。
线性分码组的性质¶
- 封闭性
许用码组模 2 加一定还在许用码组的范围,土想想也行,若要证明有
- 最小码距
最小码距为非全零码组最小码重
已知码距\(d_0\)就是俩码组的【模 2 加】求和,或【按位异或】求和
根据封闭性(许用码组模 2 加一定还在许用码组的范围)
则这一码组的 1 的数量,即码重,就是码距
则最小码重对应最小码距
也可以换一个不严谨的思路,最小码距就是从零点(多维矩阵中往往会选择)到某一最近码组的距离 零点是全零码组,那也可以推出 最小码重对应最小码距 的结论
循环码¶
\((\mathsf{n},\mathsf{k})\) 线性分组码的另一个分支,区别于汉明码
定义
【任一】许用码组循环移位后仍为【许用码组】
特点
- 同一【循环圈】(类比数电有限状态机里面的循环)的【码重】相等
- 全 0、全 1 自成循环圈
循环码的一般表达¶
码多项式 A(x)
用于表达循环码组

用码多项式表达循环码¶
联想 Verilog 中的移位寄存器 reg [7:0] cout; cout[7:0] \(=\) { cout[0],cout[7:1] };
用码多项式表达循环码,即
i 为左移位数,n 为码长
若一循环码组 \(A(x)=x^{6}+x^{5}+x^{2}+1\) , 其码长\(n=7\),现给定 \(i=3\) , 则
结论
一个长为 n 的循环码的码多项式 都是按模 \((x^{n}+1)\) 运算的一个余式
生成矩阵 G¶
不像汉明码,循环码的特征决定了用瞪眼法很难 也不是说不行🫸 设计许用码组
下面是推导过程
以下所述的码多项式是【次数】而非【维数】(高项为 0),不要混淆了
所谓生成矩阵,就是希望通过与这一矩阵相乘得到信元对应的督元,从而获得完整码组,如
但这里的 A 是码多项式 A(x),生成矩阵用于生成【循环码】
众所周知 \(\boldsymbol{G}=[I_{\boldsymbol{k}\times\boldsymbol{k}}\boldsymbol{Q}_{\boldsymbol{k}\times\boldsymbol{r}}]\) ,而
基于生成矩阵每一行都是许用码组的特性,叠加循环码的左移亦许用特征
我们惊喜的发现,只要找到一个码组,长成
接着依次往左位移,最后行交换不就得到 G(x) 了嘛?即
这里的生成矩阵和码多项式概念混叠了,能理解就行
换句话说
题外话—为什么最高次是 r 而不是 r-1?
再次强调,码多项式是【多项式】,考虑阶数而非维度
g(x)仍是 n 维,且是 r 阶
至此,假如我们已知循环码组,就可愉快地写出生成矩阵啦
例

记得转成典型 G
意外发现
最低位必须为 1,否则 g(x) 右移后,信元全为 0,但督元最高位为 1,不符合逻辑
基于例题我们又能得到一个重要性质:
所有的码多项式(许用码组)都是 g(x) 的倍数,即
h(x) 为信元码组
在码多项式的按模运算(长除法)中,我们已知
又知道了左移的定义
那能不能通过左移的关系式来构建 g(x) 的表达式呢?
但\({\sf Q}\left({\sf x}\right)\)是个很烦的东东,于是我们希望让它等于 1,怎么做?
让 g(x) 左移 k 次! (因为 \(n=k+r\) ,分子分母最高项相等)
令平移前
这里是因为 g(x) 本身也是一个码组
令平移后
则可以列出
注意,平移 k 次后不再是许用码组(条件是 \(\leq k-1\) )
整理得
\(A^{\prime}(x)=g(x)\) 和 \(A(x)=h(x)\cdot g(x)\) 代入整理得
得到结论
循环码的生成多项式 \(g(x)\) 应该是 \((x^{n}+1)\) 一个 \((n-k)\) 次因子
有点懵?看个例题就明白!
例

其他编码¶
你将在信息论与编码与他们再会
- Turbo 码
- LDPC 码
- polar 码
- ...